5.4.4 Prediction and residual values
When running linear regression analyzes through the regress command, there are two ways to extract prediction values. One way is through the use of the command regress-predict which can be used to generate a new variable with individual prediction values, residual values or Cook's distance values. These can be used for further input for various statistical purposes. The second way is to use the margins() option, which returns a fully calculated prediction value for the response variable measured by the average of all explanatory variables included.
Generate new variable with individual prediction, residual or Cook's distance values
All regression variants found in microdata.no, including regress, have associated commands that generate, among other things, residual and prediction values. These are values that can be used to analyze the data spread and for testing regression models. Prediction values can also be used as input for further analyses.
The commands have the same name as the corresponding regression command plus -predict.
Syntax:
regress-predict <variable> <variable list> [if <condition>] [,<options>]
The variables are entered in the same way as for the associated regression model that is run with the command regress.
The following values can be retrieved: Prediction values, residuals and "Cook's distance"
You decide for yourself which values you want to generate through the use of options. The result of the runs is a set of variables that contain the various values. By default, the first-mentioned value type is generated, but it is still recommended to specify this through options, as you can then also determine the name of the generated variables inside a parenthesis as shown in the syntax example below. If you run several predict commands, you must create new names for the automatically generated variables.
Syntax example:
regress-predict salary age husband wealth, residuals(res) predicted(pred) cooksd(cook)
The automatically generated variables can be used as input for further analyzes or to be displayed graphically. Current graphical commands are hexbin and histogram. By running histogram on the residual variable, you can check whether the residuals are normally distributed. The hexbin command can also be used to create anonymized scatterplots where two sets of values are combined.
For more details, it is recommended to use the help regress-predict command.
Example: Prediction and residual values analysis
Calculate predicted value for response variable measured by the average of the explanatory variables
By using the margins() option when running a linear regression model through the regress command, you can easily find the fully calculated predicted value for the response variable (Y) measured by the average value for all the respective explanatory variables.
Example:
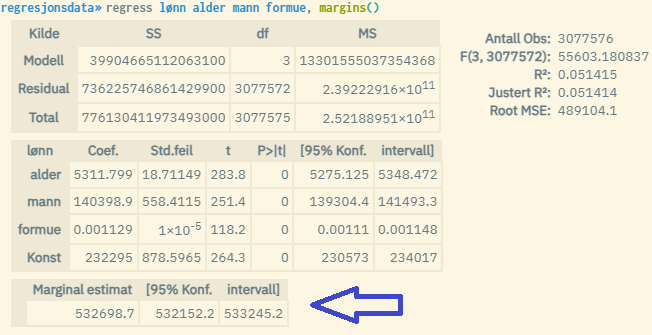
What is then returned under the model estimates is the predicted Y-value and the confidence interval. "Marginal estimate" (so predicted Y) can be interpreted as "expected value of Y measured for an average person", and is based on a standard calculation where each of the estimated coefficient values is multiplied by the average value for the associated explanatory variable (x). These are then summed together with the constant term in line with the estimated regression equation:
You can also enter a dummy variable inside the parentheses in margins(). Then you will get two extra lines returned under the model estimates, i.e. predicted Y-value for each value of the dummy variable (values 0 and 1). You then estimate predicted Y for each of the two groups with the value 0 and 1, where all other explanatory variables are measured at the average value. Note that the dummy variable you use must also be included in the regression model itself. In practice, the "expected value of Y for an average person in the respective groups 0 and 1" is then estimated. If you e.g. using the dummy variable "man", then one measures the expected value of Y for an average man and an average woman.
Example:
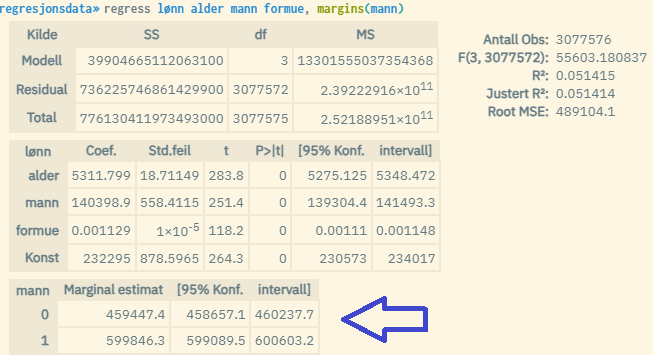
Note that when calculating predicted Y values, it is the winsorized average that is used, i.e. an average that can potentially be affected by winsorization of extreme values. In practice, this means that the average values used in the calculations of predicted values are somewhat lower than the actual values in some cases. You can read more about winsorisation here: https://microdata.no/manual/konfidensialitet#tiltak-2-winsorisering
Unlike regress-predict which generates a data set of predicted values for each unit given the actual values of the explanatory variables, the margins option calculates predicted Y values measured by the mean of the respective explanatory variables measured over the whole population. Therefore, when using the summarize command to display the mean predicted Y value based on the dataset of individual predicted values generated through regress-predict, these will not match the values reported through the margins option.